Looking for Help with Assignments?
-RUCats has 80 hours of tutoring available online and in-person. Check the tutoring tab in Canvas!
-Instructors and Lead TAs have a combined 10 hours of Office Hours, open to all sections. See times/locations here.
-Piazza (found in the Canvas sidebar) provides fast support from Course Staff and other Students. Be sure to search to see if someone has asked a similar question!
-If you need a computer to complete work on, iLab machines can be found in the CAVE (Hill 252) and surrounding rooms.
Climate and Economic Justice – 98 course points
The purpose of this assignment is to practice your linked structures.
Start your assignment early! You need time to understand the assignment and to answer the many questions that will arise as you read the description and the code provided.
Refer to our Programming Assignments FAQ for instructions on how to install VSCode, how to use the command line and how to submit your assignments.
- See this video on how to import the project into VSCode and how to submit into Autolab.
The assignment has two components:
- Coding (95 points) submitted through Autolab.
- Reflection (3 points) submitted through a form.
- Submit the reflection AFTER you have completed the coding component.
- Be sure to sign in with your RU credentials! (netid@scarletmail.rutgers.edu)
- You cannot resubmit reflections but you can edit your responses before the deadline by clicking the Google Form link, signing in with their netid, and selecting “Edit your response”
Overview
Welcome to the Climate and Economic Justice assignment!
In this assignment, you’ll be working with community data from various regions to explore the intersection of climate and economic justice. The provided data includes information about racial demographics, pollution levels, flood risks, poverty rates, and more. Your goal is to process this data using linked lists and analyze the social and environmental aspects of different communities.
- Communities data analysis is an important tool to understand communities aspects. For example, flood risk and high PM2.5 levels to name a few.
- The data can help understand which communities are susceptible to flooding, or if disadvantaged communities are more susceptible to flooding than non-disadvantage communities.
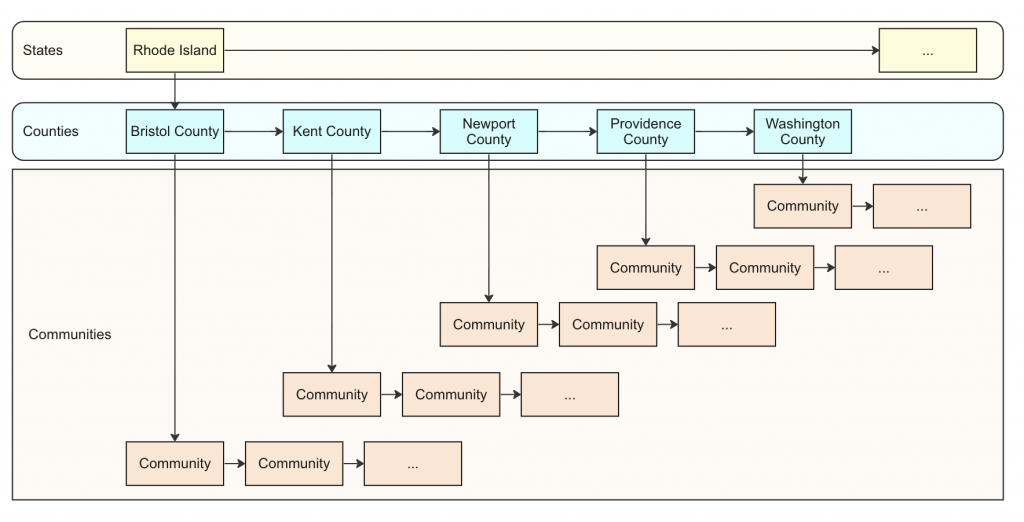
In this assignment, you’ll implement methods in the ClimateEconJustice.java class to create a 3-layered linked list structure consisting of states, counties, and communities. Each layer is interconnected, allowing you to navigate through the data hierarchy. Your methods will carry out operations on this linked structure to gain insights from the community data.
- This is not the optimal data structure to hold this dataset but it will give you practice in linked structures.
Implementation
Overview of files provided
You will be working with a Java package named “climate,” which contains several Java classes and a CSV data file. Here’s an overview of each file:
- ClimateEconJustice.java
This file is where you will complete the implementation of various methods to process and analyze community data. The methods in this class will create a linked list structure and perform calculations based on the provided data. You will be writing your code in this file. DO NOT edit the provided methods or the methods signatures of any method. This is the file you submit. - StateNode.java
This class represents a state node in the linked list structure. It contains information about the state’s name, a reference to the next state node, and the first county in that state. Do not modify this file. - CountyNode.java
This class represents a county node in the linked list structure. It contains information about the county’s name, the next county, and the first community in that county. Do not modify this file. - CommunityNode.java
This class represents a community node in the linked list structure. It contains information about the community’s name, a reference to the next community node, and a Data object that stores various attributes of the community. Do not modify this file. - CommunityData.java
This class contains attributes that store data about a community, such as racial demographic percentages, pollution levels, flood risks, and poverty rates. Getter and setter methods are provided to access and modify these attributes. Do not modify this file. - StdIn and StdOut, which are used by the driver. Do not edit these classes.
- Multiple text files () contains comprehensive data about various communities, including attributes beyond those required for the assignment. The data includes community names, county names, state names, racial demographic percentages, pollution levels, flood risks, poverty rates, and more. For the assignment, you will need to use the split function to extract only the relevant attributes specified in the assignment instructions.
ClimateEconJustice.java
- DO NOT add new import statements.
- DO NOT change any of the method’s signatures.
Methods to be implemented by you:
createLinkedStructure
This method is responsible for reading data from a CSV file and constructing a 3-layered linked list structure. The instance variable firstState is a reference to the front of the layered linked list you will create.
This method reads the input file and calls the following three methods in order: addToStateLevel, addToCountyLevel, and addToCommunityLevel. Each row of the CSV contains communities and comma-separated information about them, besides the header which is skipped.
- To help you visualize how the linked structure will look like, refer to the diagram below which provides a small example for Rhode Island.
- To test addToStateLayer, addToCountyLevel, and addToCommunityLevel, call createLinkedStructure in the driver. It will work unchanged to test these methods.
- All methods following addToCommunityLevel require the structure to be created using createLinkedStructure. Call createLinkedStructure in the driver before testing other methods.
Do not edit this method, it has been written for you.
1. addToStateLevel
This method adds a single state to the layered linked list starting at firstState. Add to the end of the list, and if the state already exists in the list do nothing.
Submit this method to early submission once you have completed it for extra credit.
To complete this method:
- Given a line from the input file, split (string_name.split(“,”)) each line to extract information such as community, county, and state names, along with various attributes. The indices for all the contents required are as follows:
- Community: index 0
- County: index 1
- State: index 2
- Percent African American: index 3
- Percent Native: index 4
- Percent Asian: index 5
- Percent White: index 8
- Percent Hispanic: index 9
- Disadvantaged: index 19
- PM Level: index 49
- Chance of Flood: index 37
- Poverty Line: index 121
- In this method you will ONLY use the states’ name (index 2)
- Create instances of StateNode classes to store the extracted data.
- In later methods you will build the linked list structure by adding states, counties, and communities using setNext and setDown methods.
2. addToCountyLevel
This method reads a county and links it to its corresponding state.
- If a county already exists in the list, do nothing.
To complete this method:
- Read a line the same way you did in the previous method. You will use indices 1 and 2 for this method.
- Search for the state you want to link a county to, and access its county list through its down method.
- Add to the end of the county list, doing nothing if it’s present.
3. addToCommunityLevel
This method reads a community and links it to its corresponding county.
To complete this method:
- Read a line the same way you did in the previous method. For reference, here are the indices used:
- Community: index 0
- County: index 1
- State: index 2
- Percent African American: index 3
- Percent Native: index 4
- Percent Asian: index 5
- Percent White: index 8
- Percent Hispanic: index 9
- Disadvantaged: index 19
- PM Level: index 49
- Chance of Flood: index 37
- Poverty Line: index 121
- You will need to create a Data object to store the data from this community; it will be stored inside the CommunityNode.
- Search for the state corresponding to this community and then the county by using the state’s down reference. Then, add the CommunityNode to the end of the community list (access through county’s down reference).
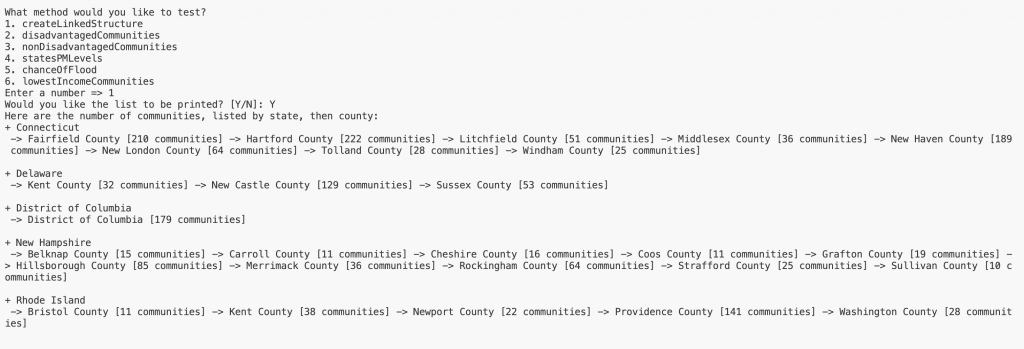
This is the expected output for TestCommunityData.csv when addToStateLayer, addToCountyLayer, and addToCommunityLayer are complete. As you complete these methods, you will build each one of these layers starting from states.
4. disadvantagedCommunities
This method calculates the number of communities that have a certain percentage or higher of a particular racial demographic and are identified as disadvantaged.
To complete this method:
- Start by traversing the linked list structure layer by layer.
- Once you reach the community layer, count the number of communities that have said percentage or higher of the racial demographic and are also identified as disadvantaged.
- Utilize the getAdvantageStatus method to determine disadvantaged status.
- Return the count of the communities that meet these criteria.

5. nonDisadvantagedCommunities
Similar to the previous method, this method calculates the number of communities that have a certain percentage or higher of a particular racial demographic and are identified as non-disadvantaged.
To complete this method:
- Again, traverse the linked list structure layer by layer.
- Once you reach the community layer, count the number of communities that have said percentage or higher of the racial demographic and are also identified as non-disadvantaged.
- Utilize the getAdvantageStatus method to determine disadvantaged status.
- Return the count of communities meeting these criteria.
Note: getAdvantageStatus() returns the disadvantaged value that you read in addToCommunityLevel and added to each community’s Data object: it is a String that is either “True” or “False”. True indicates a community is disadvantaged, False otherwise.

6. statesPMLevels
This method identifies states with pollution levels (PM2.5) equal to or exceeding a provided threshold.
To complete this method:
- Traverse the linked list structure.
- Once you reach the community layer, check if each community has a recorded pollution level equal to or higher than the pollution level entered.
- Identify states containing communities with pollution levels meeting the threshold.
- Store these states in an ArrayList and return the list.
This is the expected output for this method when tested in the driver using TestCommunityData.csv. You must create the linked structure by calling createLinkedStructure in the driver before testing this method:

7. chanceOfFlood
This method counts the number of communities that have a chance of flooding equal to or exceeding a provided percentage.
To complete this method:
- Traverse the linked list structure.
- Once you reach the community layer, count the number of communities that have a chance of flooding equal to or higher than the specified threshold.
- Return the total count of communities meeting this criterion.

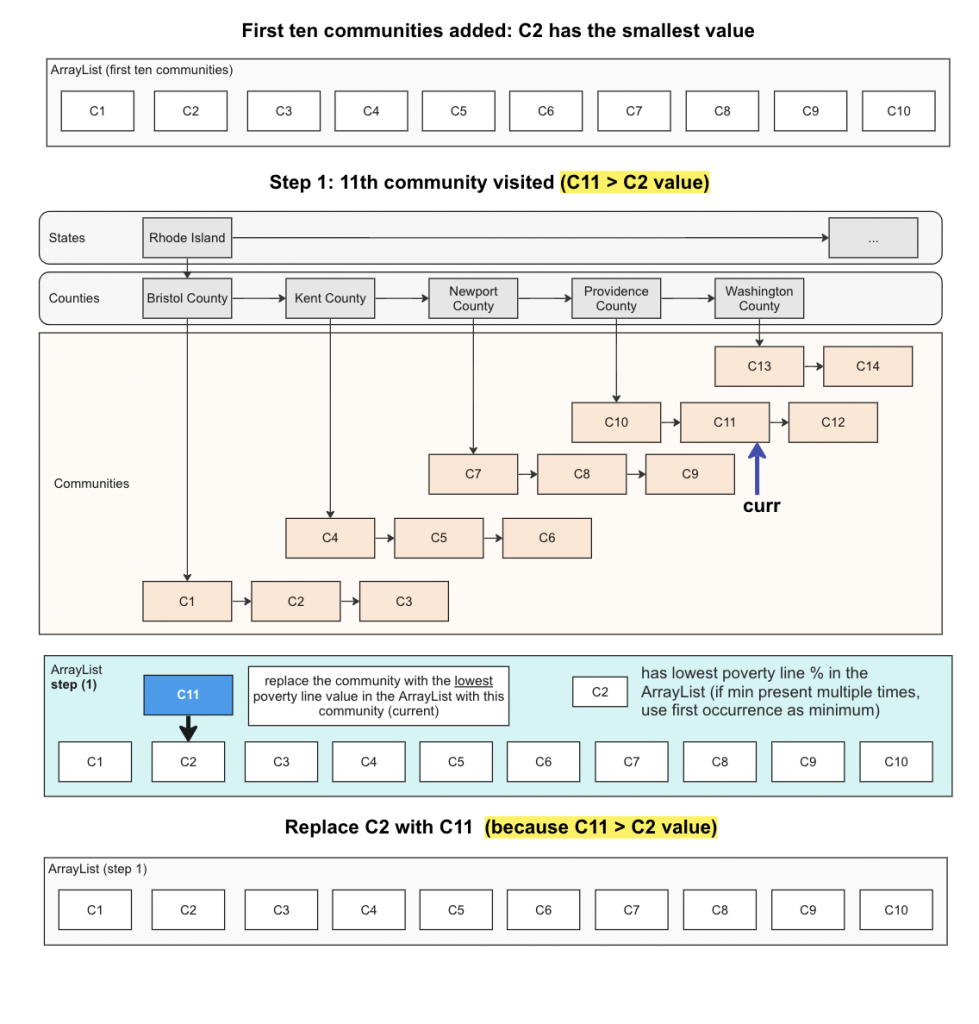
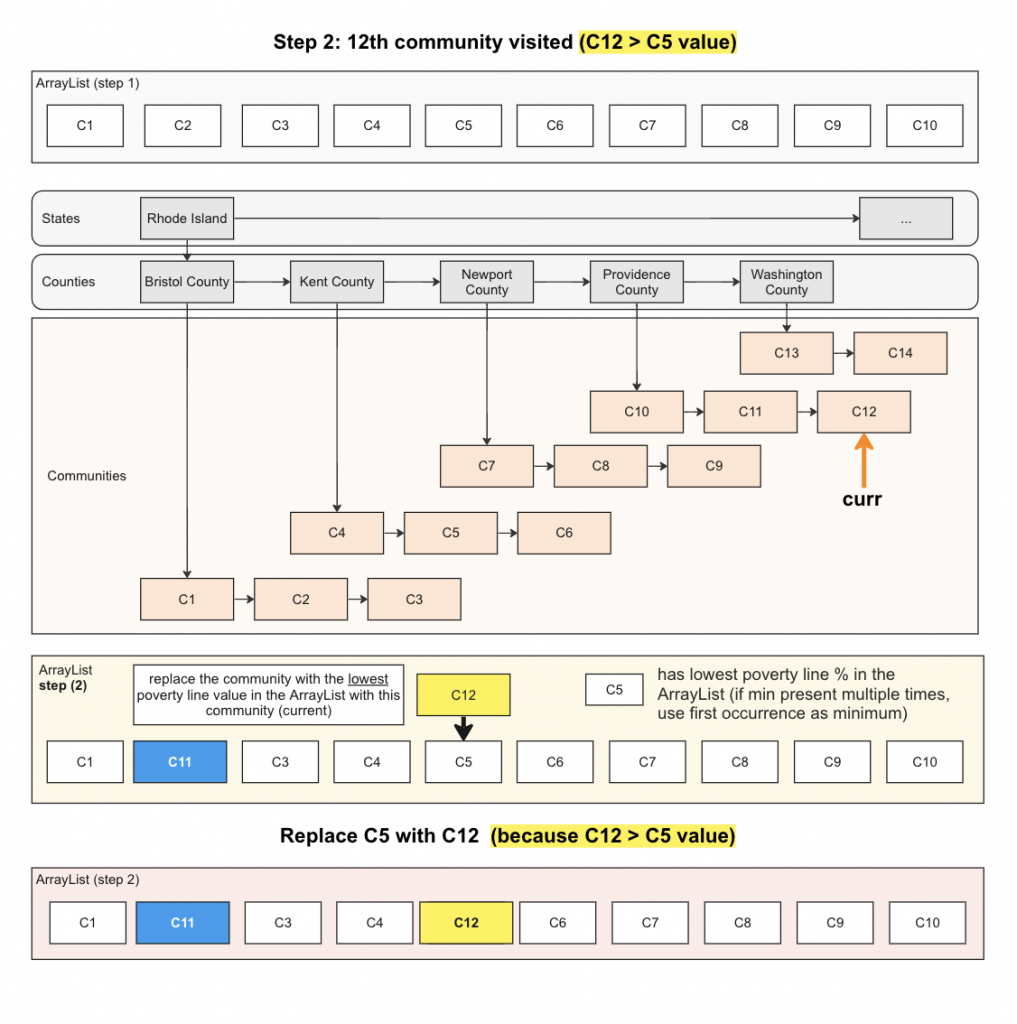
8. lowestIncomeCommunities
This method identifies the 10 communities with the lowest incomes within a specific state.
To complete this method:
- Traverse the linked list structure until you reach the specified state.
- Then, traverse the linked list connected to that state until you reach the community layer.
- Iterate through the communities, maintaining an ArrayList of the 10 lowest-income communities – you can use the getPercentPovertyLine method of the community’s corresponding Data object.
- As you iterate, if there are ten communities in the ArrayList:
- Find the community with the lowest percent poverty line. If there are multiple communities with the same (lowest) percent, use the first one.
- Replace the lowest poverty line community with the community you are at IF the current community has a higher percent poverty line than the one with the lowest.
- As you iterate, if there are ten communities in the ArrayList:
- Update this list as you encounter lower income communities, until you reach the end of the communities list.
Refer to the diagram below for steps 3 and 4:
Note 1: the ArrayList order does not matter.
Note 2: Use list.set(index, elementToReplaceWith) to replace an element stored at an index with the object passed through parameters in the same index.
This is the expected output for this method when tested in the driver using TestCommunityData.csv. You must create the linked structure by calling createLinkedStructure in the driver before testing this method:

Implementation Notes
- YOU MAY only update the methods with the WRITE YOUR CODE HERE line.
- DO NOT add any instance variables to the ClimateEconJustice class.
- DO NOT add any public methods to the ClimateEconJustice class.
- YOU MAY add private methods to the ClimateEconJustice class.
- DO NOT use System.exit()
VSCode Extensions
You can install VSCode extension packs for Java. Take a look at this tutorial. We suggest:
Importing VSCode Project
- Download ClimateAndEconJustice.zip from Autolab Attachments.
- Unzip the file by double clicking.
- Open VSCode
- Import the folder to a workspace through File > Open
Executing and Debugging
- You can run your program through VSCode or you can use the Terminal to compile and execute. We suggest running through VSCode because it will give you the option to debug.
- How to debug your code
- If you choose the Terminal:
- first navigate to ClimateEconJustice directory/folder
- to compile: javac -d bin src/climate/*.java
- to execute: java -cp bin climate.Driver
- first navigate to ClimateEconJustice directory/folder
Before submission
Collaboration policy. Read our collaboration policy here.
Submitting the assignment. Submit ClimateEconJustice.java separately via the web submission system called Autolab. To do this, click the Assignments link from the course website; click the Submit link for that assignment.
Getting help
If anything is unclear, don’t hesitate to drop by office hours or post a question on Piazza.
- Find instructors office hours here
- Find tutors office hours on Canvas -> Tutoring
- Find head TAs office hours here
- In addition to office hours we have the CAVE (Collaborative Academic Versatile Environment), a community space staffed with lab assistants which are undergraduate students further along the CS major to answer questions.
Problem by Navya Sharma
