Trie – 100 course points
The purpose of this assignment is to broaden your understanding of a tree structure.
Refer to our Programming Assignments FAQ for instructions on how to install VSCode, how to use the command line and how to submit your assignments.
Autolab will be ready to receive submissions on Friday, March 5.
Summary
You will write an application to build a tree structure called Trie for a dictionary of English words, and use the Trie to generate completion lists for string searches.
Trie Structure
A Trie is a general tree, in that each node can have any number of children. It is used to store a dictionary (list) of words that can be searched on,
in a manner that allows for efficient generation of completion lists.
The word list is originally stored in an array, and the trie is built off of this array. Here are some examples of word lists and the tries built to store the words, followed by an explanation of the trie structure and its relationship to its source word list.

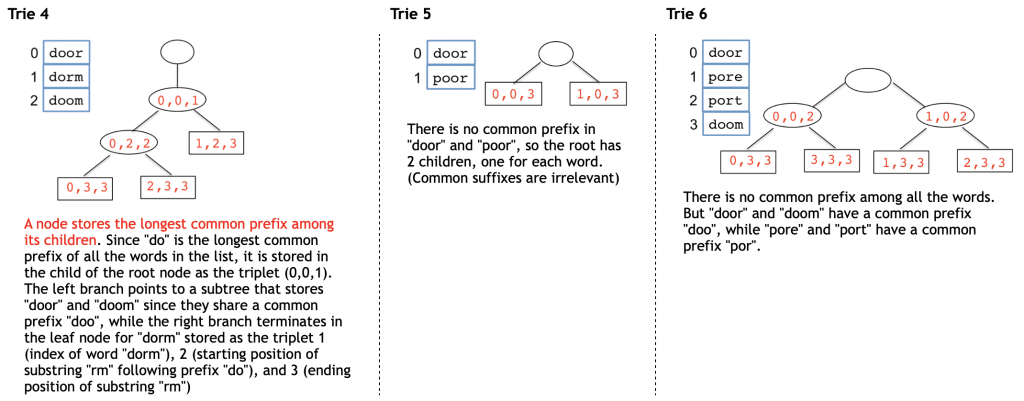
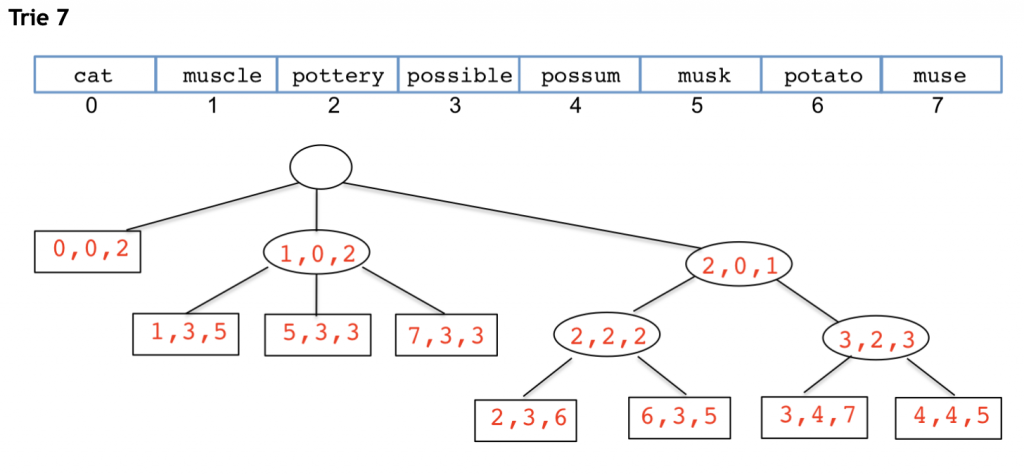
Special Notes
- Every leaf node represents a complete word, and every complete word is represented by some leaf node. (In other words, internal nodes do not represent complete words, only proper prefixes.)
- No node, except for the root, can have a single child. In other words, every internal node has at least 2 children. Why? Because an internal node is a common prefix of several words. Consider these trees, in each of which an internal node has a single child (incorrect), and the equivalent correct tree:
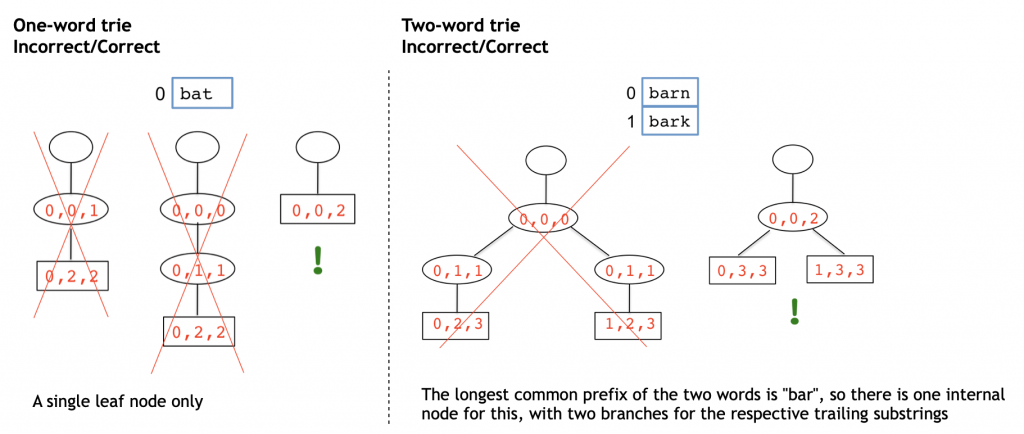
A trie does NOT accept two words where one entire word is a prefix of the other, such as “free” and “freedom”.
(You will not come across this situation in any of the test cases for your implementation.)
The process to build the tree (described in the Building a Trie section below), will create a single child of the root for the longest common prefix “free”, and this node will have a single child, a leaf node for the word “freedom”. But this is an incorrect tree because it will (a) violate the constraint that no node aside from the root can have a single child, and (b) violate the requirement that every complete word be a leaf node (the complete word “free” is not a leaf node).

On the other hand, a tree with two leaf node children off the root node, one for the word “free” and the other for the word “freedom” will be incorrectbecause the longest common prefix MUST be a separate node. (This is the basis of completion choices when the user starts typing a word.)
Data Structure
Since the nodes in a trie have varying numbers of children, the structure is built using linked lists in which each node has three fields:
- substring (which is a triplet of indexes)
- first child, and
- sibling, which is a pointer to the next sibling.
Here’s a trie and the corresponding data structure:
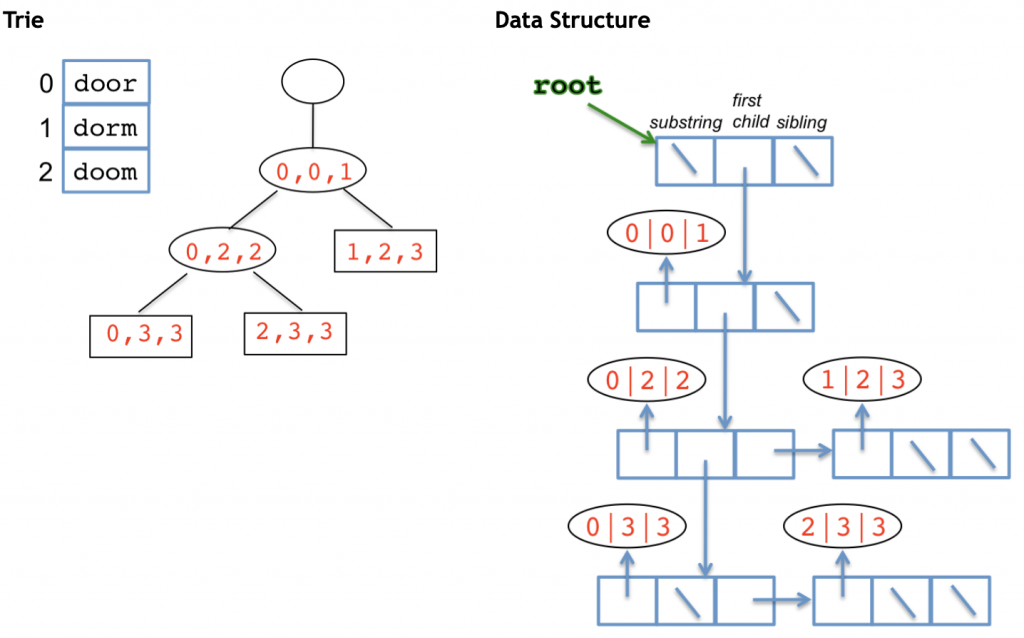
Building a Trie
A trie is built for a given list of words that is stored in array. The word list is input to the trie building algorithm. The trie starts out empty, inserting one word at a time.
Example 1
The following sequence shows the building of the above trie, one word at a time, with the complete data structure shown after each word is inserted.
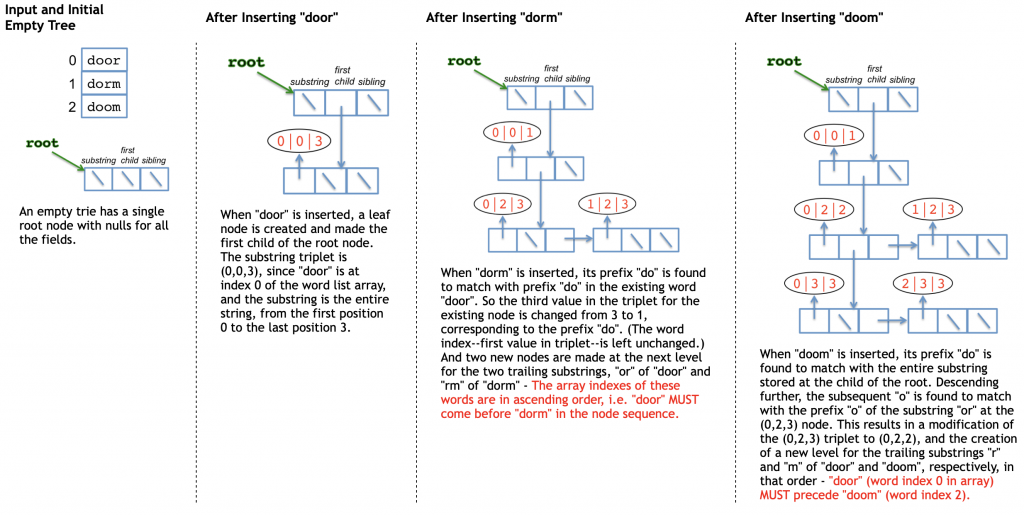
Example 2
This shows the sequence of inserts in building Trie 7 shown earlier.

Prefix Search
Once the trie is set up for a list of words, you can compute word completions efficiently.
For instance, in the trie of Example 2 above (cat, muscle, …), suppose you wanted to find all words that started with “po” (prefix). The search would start at the root, and touch the nodes [0,0,2],(1,0,2),(2,0,1),(2,2,2),(3,2,3),[2,3,6],[6,3,5],[3,4,7],[4,4,5] . The nodes marked in red are the ones that hold words that begin with the given prefix.
Note that NOT ALL nodes in the tree are examined. In particular, after examining (1,0,2), the entire subtree rooted at that node is skipped. This makes the search efficient. (Searching all nodes in the tree would obviously be very inefficient, you might as well have searched the word array in that case, why bother building a trie!)
Implementation
This zip file contains the assignment files. Download and unzip in your computer. You will see there is a Trie directory with:
- samp2 directories/folders
- src: contains the folder trie with Trie.java, TrieNode.java, and TrieApp.java
- bin: contains the folder trie with the class files after the assignment is compiled
- 6 files
- words0.txt, words1.txt, words2.txt, words3.txt, words4.txt: sample word files. The first line of a word file is the number of the words, and the subsequent lines are the words, one per line.
- Makefile: used to automate building and executing the target program
You will implement the following methods in the Trie class:
- (65 pts) buildTrie: Starting with an empty trie, builds it up by inserting words from an input array, one word at a time. The words in the input array are all lower case, and comprise of letters ONLY.
- (35 pts) completionList: For a given search prefix, scans the trie efficiently (as describes in the Prefix Search section above), gathers and returns an ArrayList of references to all leaf TrieNodes that hold words that begin with the search prefix (you should NOT create new nodes.) For instance, in the trie of Example 2 above, for search prefix “po” your implementation should return a list of references to these trie leaf nodes: [2,3,6],[6,3,5],[3,4,7],[4,4,5].NOTE:
- The order in which the leaf nodes appear in the returned list does not matter.
- You may NOT search the words array directly, since that would defeat the purpose of building the trie, which allows for more efficient prefix search. See the Prefix Searchsection above. If you search the array, you will NOT GET ANY credit, even if your result is correct.
- If your prefix search examines unnecessary nodes (see Prefix Search section above), you will NOT GET ANY credit, even if your result is correct.
Make sure to read the comments in the code that precede classes, fields, and methods for code-specific details that do not appear here. Also, note that the methods are all static, and the Trie has a single private constructor, which means NO Trie instances are to be created – all manipulations are directly done via TrieNode instances.
You may NOT MAKE ANY CHANGES to the Trie.java file EXCEPT to (a) fill in the body of the required methods, or (b) add private helper methods. Otherwise, your submission will be penalized.
You may NOT MAKE ANY CHANGES to the TrieNode class (you will only be submitting Trie.java). When we test your submission, we will use the exact same version of TrieNodethat we shipped to you.
Compiling and Executing
Once inside the Trie directory, type:
- javac -d bin src/trie/*.java to compile
- java -cp bin trie.TrieApp to execute
If you have a unix operating system (Linux or Mac OS) you CAN use the Makefile file provided. Once inside the Trie directory type:
- make to compile
- make run to execute
- make clean remove all the .class files
Testing
You can test your program using the supplied TrieApp driver. It first asks for the name of an input file of words, with which it builds a trie by calling the Trie.buuldTree method. After the trie is built, it asks for search prefixes for which it computes completion lists, calling the Trie.completionList method.
Several sample word files are given with the project, directly under the project folder. (words0.txt, words1.txt, words2.txt, words3.txt, words4.txt). The first line of a word file is the number of the words, and the subsequent lines are the words, one per line.
There’s a convenient print method implemented in the Trie class that is used by TrieApp to output a tree for verification and debugging ONLY. Our testing script will NOT look at this output – see the Grading section below.
When we test your program:
- There will be at least one word in every test (no empty tests).
- Words will ONLY have letters in the alphabet.
- All words–for building the trie as well as for prefix searches–will be input in lower case.
- We will NOT input duplicate words.
- We will NOT input two words such that one is a prefix of the other, as in “free” and “freedom”, i.e. a complete word will not be a prefix of another word.
Here are a couple of examples of running TrieApp:
The first run is for words3.txt:
Enter words file name => words3.txt
TRIE
---root
|
doo
---(0,0,2)
|
door
---(0,3,3)
|
doom
---(3,3,3)
|
por
---(1,0,2)
|
pore
---(1,3,3)
|
port
---(2,3,3)
completion list for (enter prefix, or 'quit'): do
door,doom
completion list for: quit
The second run is for words4.txt:
Enter words file name => words4.txt
TRIE
---root
|
cat
---(0,0,2)
|
mus
---(1,0,2)
|
muscle
---(1,3,5)
|
musk
---(5,3,3)
|
po
---(2,0,1)
|
pot
---(2,2,2)
|
pottery
---(2,3,6)
|
potato
---(6,3,5)
|
poss
---(3,2,3)
|
possible
---(3,4,7)
|
possum
---(4,4,5)
completion list for (enter prefix, or 'quit'): pos
possible,possum
completion list for: mu
muscle,musk
completion list for: pot
pottery,potato
completion list for: quit
Try these tests with your implementation – your Trie printout MUST look IDENTICAL to the above. If your tree looks different, either your program logic is incorrect, or there is something different in the sequence of word inserts. In either case, you will not get any credit, so make sure you fix your code.
Also try the other sample word files. AND, try with word files of your own, formatted exactly like the sample word files – first line is number of words, then one word per subsequent line.
Go over the TrieApp code to understand how the Trie methods are called, and how the returned array list from completionList is processed to actually print the completion words.
Grading
The buildTrie method will be graded by comparing the tree structure resulting from your implementation, with the correct tree structure produced by our implementation. We will NOT be looking at the printout of the tree, the print method in the Trie class (used by TrieApp as in the above test examples) is for your convenience only.
The completionList method will be graded by inputting prefix strings to some of the trees created in buildTrie. However, these trees will be created by our correct implementation of buildTrie. In other words, to test your completionList implementation, we will NOT use your buildTrie implementation at all. This is fully for your benefit, because if your buildTrie implementation is incorrect, it will not adversely affect the credit you get for your completionList implementation.
The nodes you return from the completionList method must belong to the Trie. If the returned list has one or more independent nodes created outside of the Trie (even if they have the correct data), you will not get any credit.
Before submission
- Collaboration policy. Read our collaboration policy here.
- Submitting the assignment. Submit Trie.java separately via the web submission system called Autolab. To do this, click the Assignments link from the course website; click the Submit link for that assignment.
Getting help
If anything is unclear, don’t hesitate to drop by office hours or post a question on Piazza. Find instructors office hours by clicking the Staff link from the course website. In addition to office hours we have the CAVE (Collaborative Academic Versatile Environment), a community space staffed with lab assistants which are undergraduate students further along the CS major to answer questions.
